What we want to achieve in this setup is an intelligent load balancer that can do fail-over, but that excludes the members which are known to be in 'down' state from these fail-over tries.
In case none of the members is considered ‘up’, we want an immediate error-response and no extra waiting times for retries to backends that will probably fail. One of the reasons for such an approach might be that we want to isolate problems with a specific backend and make sure our Datapower appliance is not affected by a huge number of open connections (e.g. due to to a very high load and a relatively large time-out value). If the amount of open connections keeps on rising we will eventually reach the boundaries of the appliance and start receiving out-of-memory errors...
First of all a short explanation on the different states of a member of the load balancer group:
- ‘up’: this is the default state of a member of the load balancer when it is added, but this state can also be reached when a member that was ‘down’ succeeds a health check.
- ‘down’: this state can be reached when a health check on this member failed or when the member is manually disabled.
- ‘softdown’: aka dampened, when an actual request reaches a connection error, the state of the member that caused the error is set to ‘softdown’ for a period specified in the ‘damp time’.
Healthcheck
After adding the members to the load balancer group we are going to add a health check. The default health check sends an empty soap-request and validates the received response against the entered xpath. Since the default xpath is ‘/’ the health check will be valid if any xml-response is received.
One option needs some extra attention: the ‘Timeout’ value. This value represents the amount of seconds before the health check fails with a time out. However, since the health check request is done using a user agent object, in reality the time out of the user agent is the one that is used.
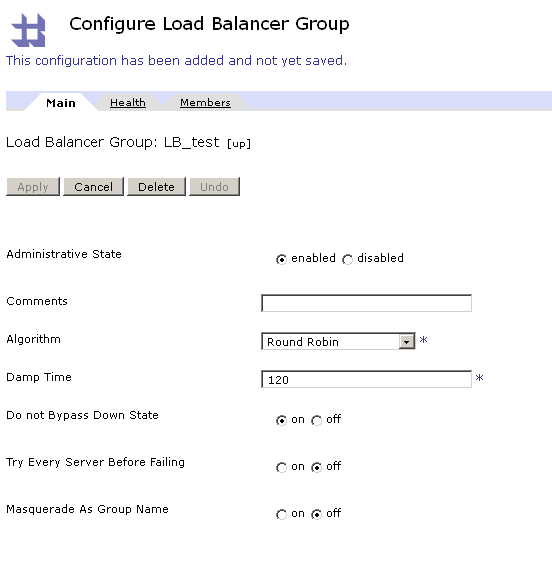
Main load balancer group settings
The options that need some extra clarification here are ‘Do Not Bypass Down State’ and ‘Try Every Server Before Failing’.- ‘Do Not Bypass Down State’: This property should ensure that when all members of the load-balancing group are down and a new request for that group is made, no attempt will be made to connect. However you should note that the load balancer is only behaving like this when this property is set to ‘On’ AND the property ‘Try Every Server Before Failing’ is set to off.
- ‘Try Every Server Before Failing’: As stated above, this property overrules the ‘Do Not Bypass Down State’ when it is set to ‘On’. The Datapower help-file will tell you the following:

This text is a bit confusing, since in reality we observed the following behavior: not only dampened and healthy members, but also unhealthy members are tried. This can cause some serious problems in case of time-out errors on multiple members, since each member adds this time-out to the total execution time... When this property is set to ‘Off’, the behavior observed is that in case of a failed connection attempt, the next member in state ‘Up’ is tried.
For the intelligent load balancer that we want to create we need to set the property ‘Do Not Bypass Down State’ to ‘On’ and the property ‘Try Every Server Before Failing’ to ‘Off’ as can be seen in the screenshot below.
Conclusion
With only a few configuration steps we can create an intelligent load balancer. The load balancer actively executes health checks with SOAP-calls and maintains a list with the status of its members. When a connection error occurs during an actual call from a client it automatically retries to make a connection with one of the known healthy members. When no member is ‘Up’ the call will directly fail and therefore prevent an exponential rise of open connections in case of a high load.
Author: Tim
No comments:
Post a Comment